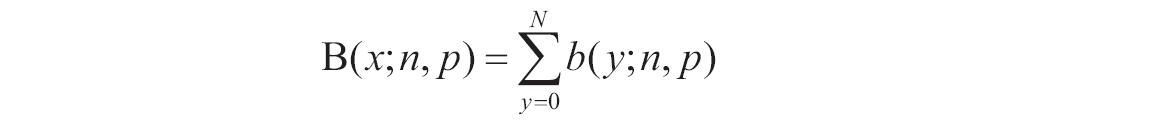COUNT函数用于计算返回包含数字的单元格的个数以及返回参数列表中的数字个数。利用函数COUNT可以计算单元格区域或数字数组中数字字段的输入项个数。COUNT函数的语法如下。
COUNT(value1,value2,...)
其中参数value1,value2,…是可以包含或引用各种类型数据的1到255个参数,但只有数字类型的数据才计算在内。
典型案例
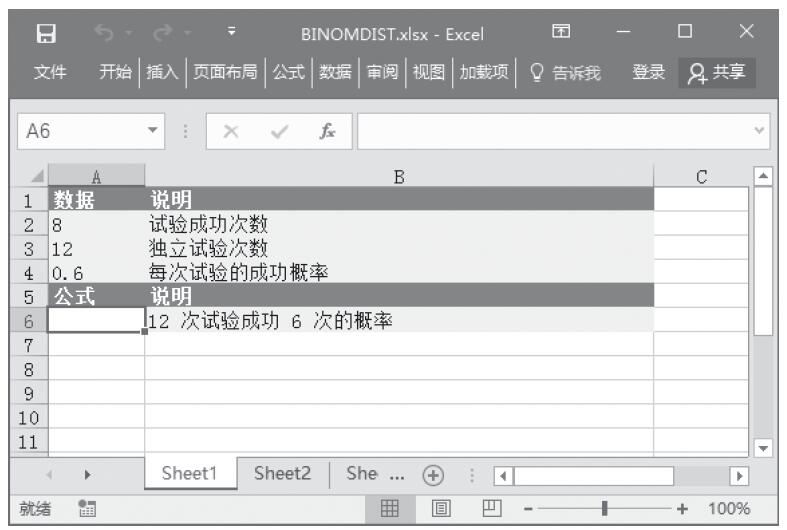
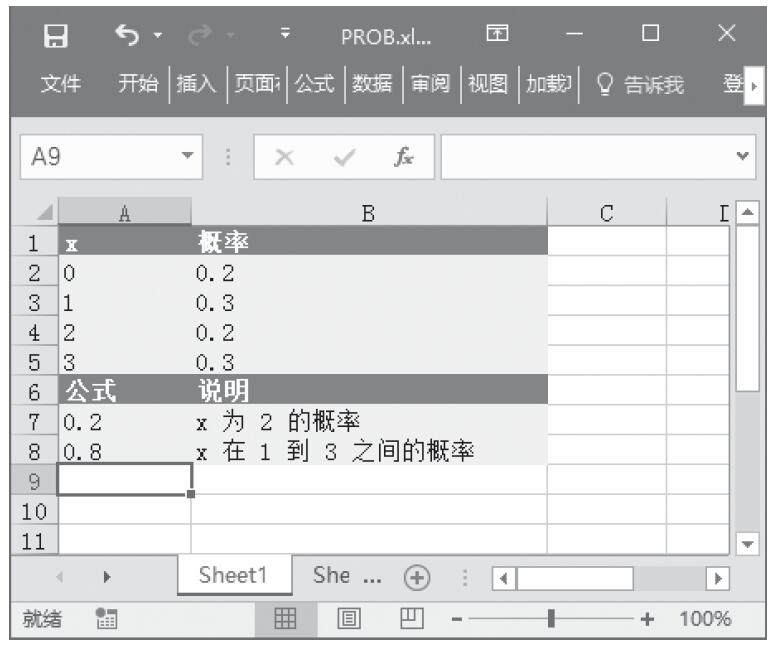
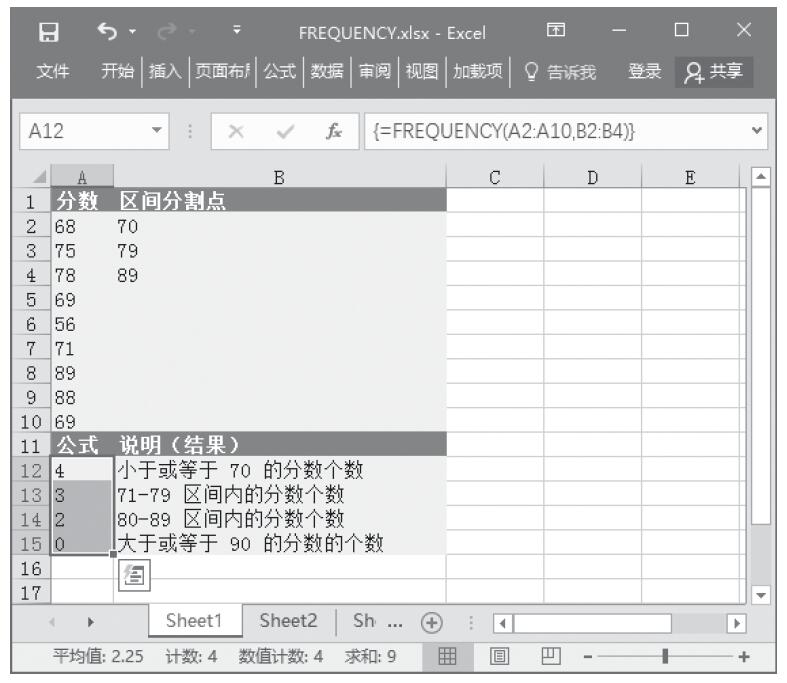
已知一组数据,计算数据中包含数字的单元格的个数以及返回参数列表中的数字个数。基础数据如图16-47所示。
步骤1:打开例子工作簿“COUNT.xlsx”。
步骤2:在单元格A10中输入公式“=COUNT(A2:A8)”,用于计算上列数据中包含数字的单元格的个数。
步骤3:在单元格A11中输入公式“=COUNT(A5:A8)”,用于计算上列数据的最后4行中包含数字的单元格的个数。
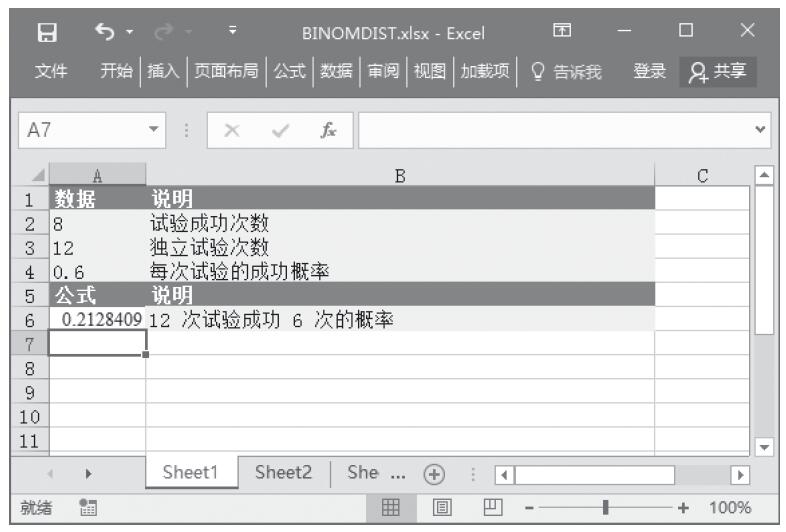
步骤4:在单元格A12中输入公式“=COUNT(A2:A8,2)”,用于计算上列数据中包含数字的单元格以及包含数值2的单元格的个数。计算结果如图16-48所示。
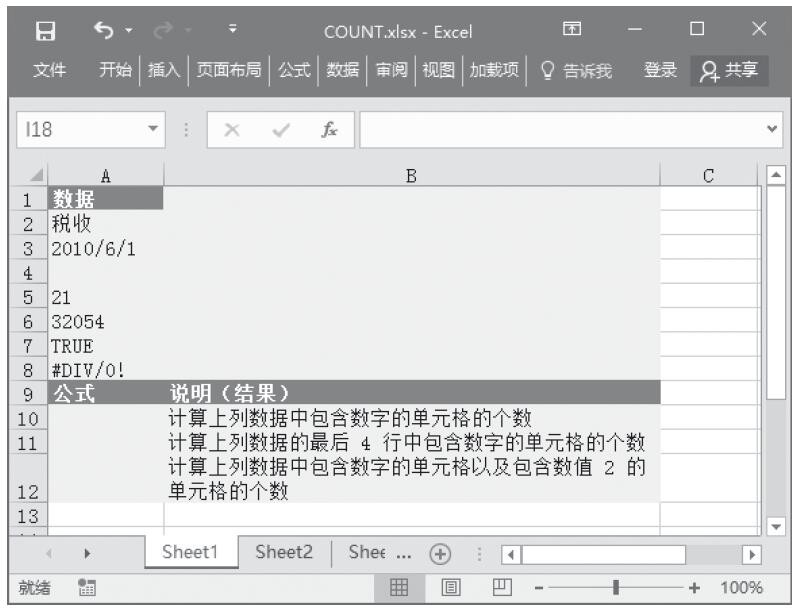
图16-47 基础数据
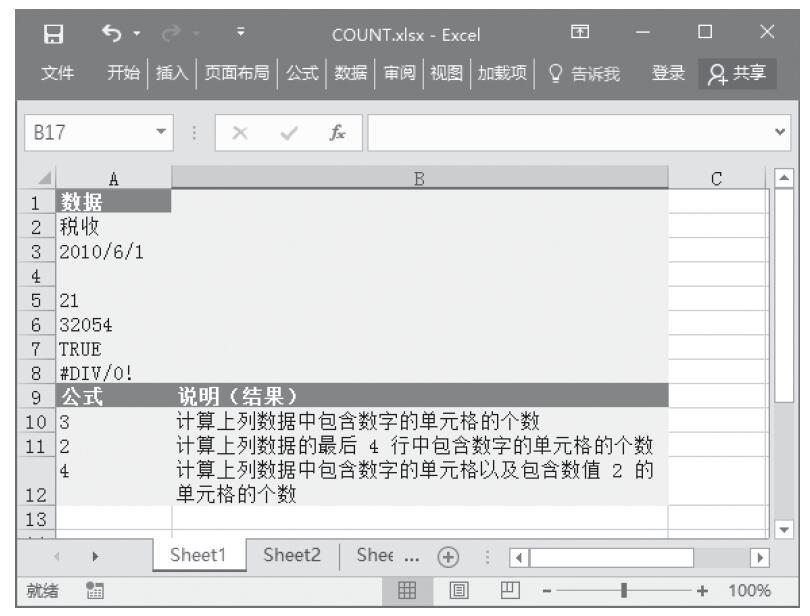
图16-48 计算结果
使用指南
数字参数、日期参数或者代表数字的文本参数被计算在内。逻辑值和直接键入到参数列表中代表数字的文本被计算在内。如果参数为错误值或不能转换为数字的文本,将被忽略;如果参数是一个数组或引用,则只计算其中的数字。
数组或引用中的空白单元格、逻辑值、文本或错误值将被忽略。如果要统计逻辑值、文本或错误值,则需要使用COUNTA函数。



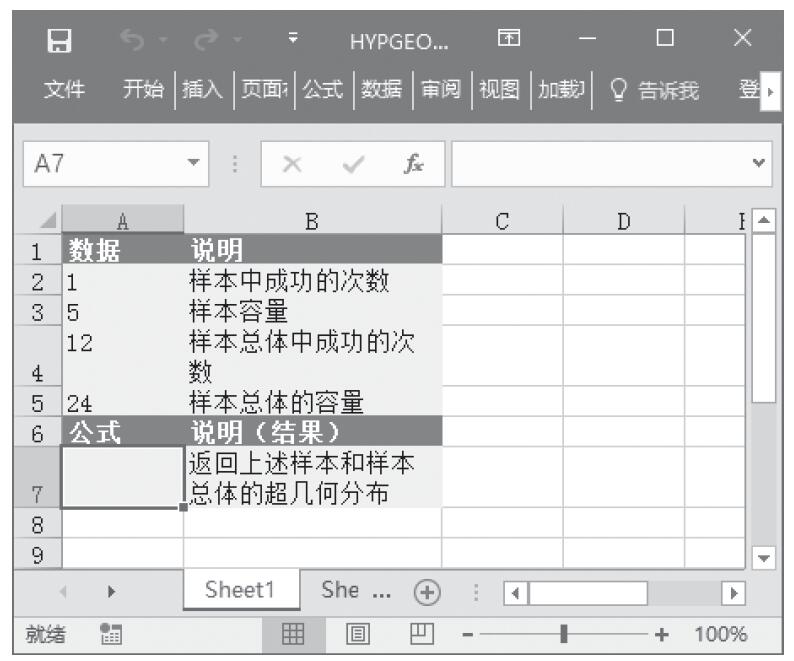
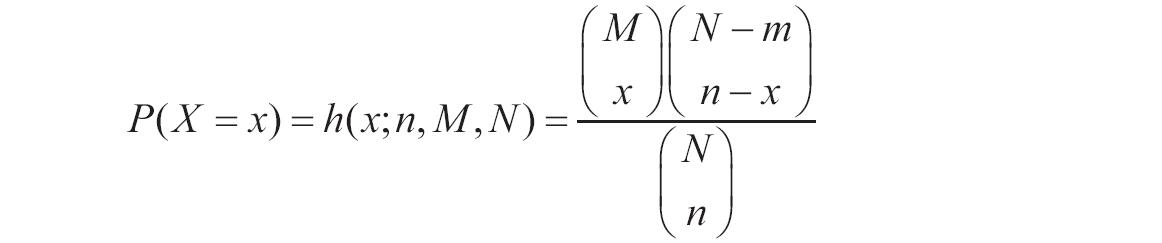
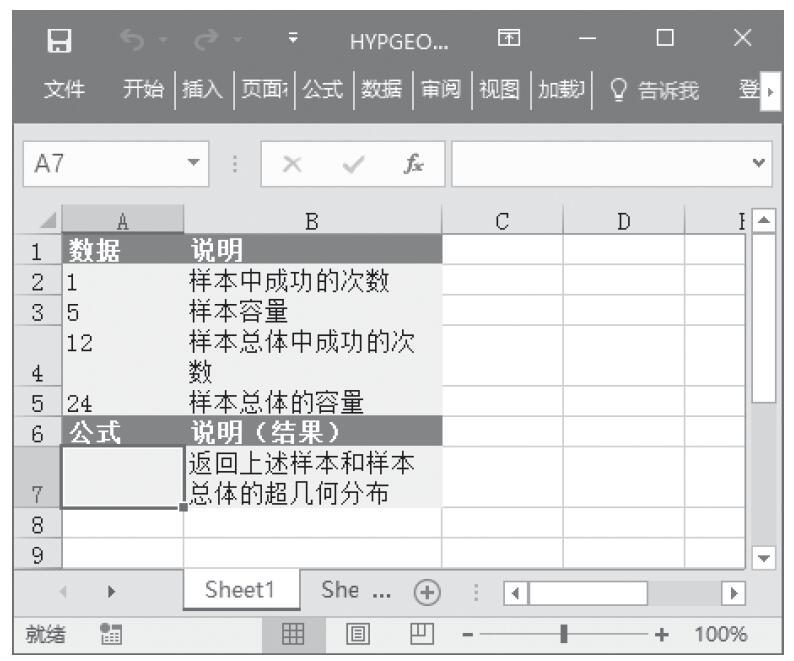
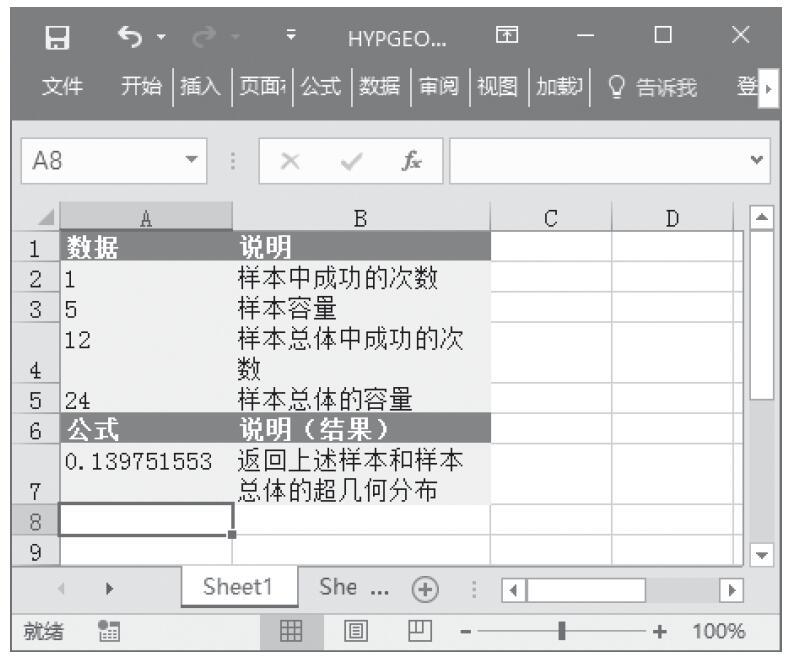
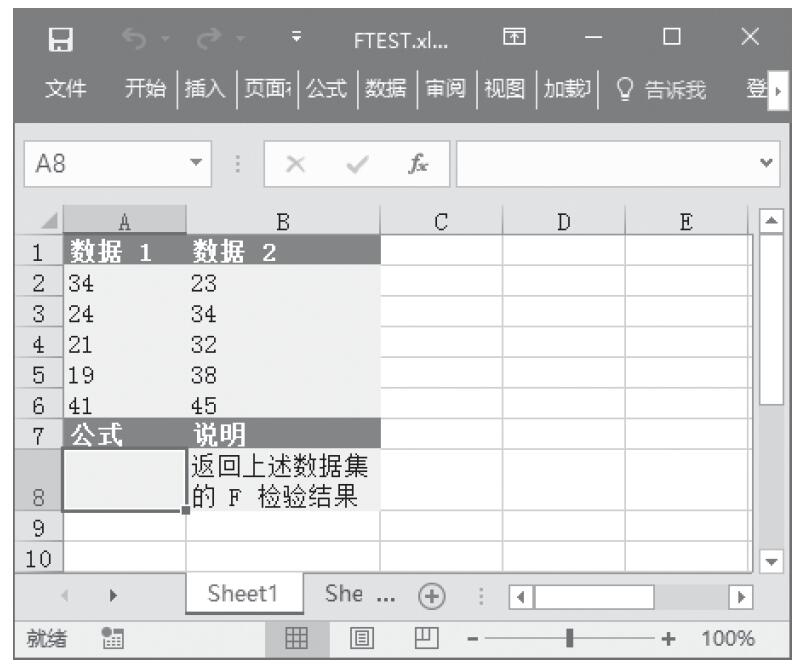
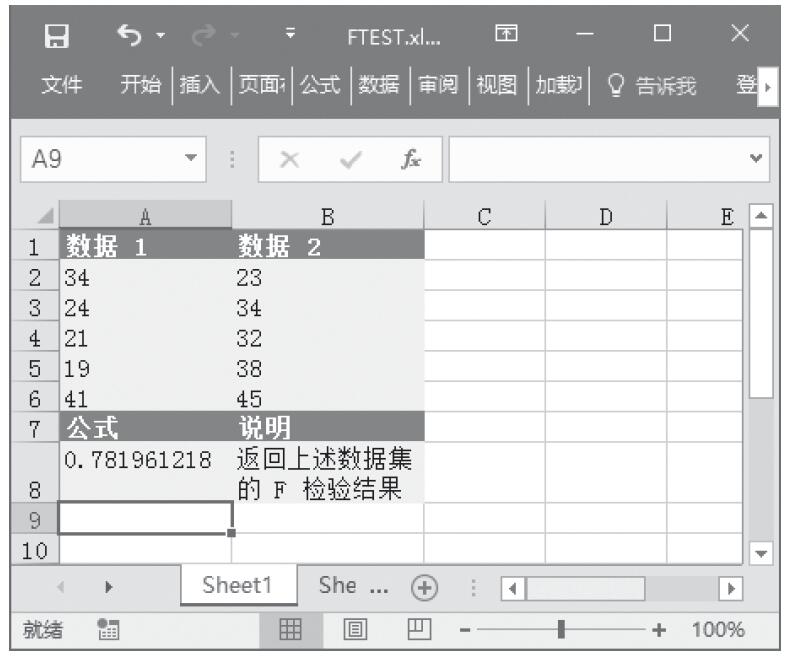
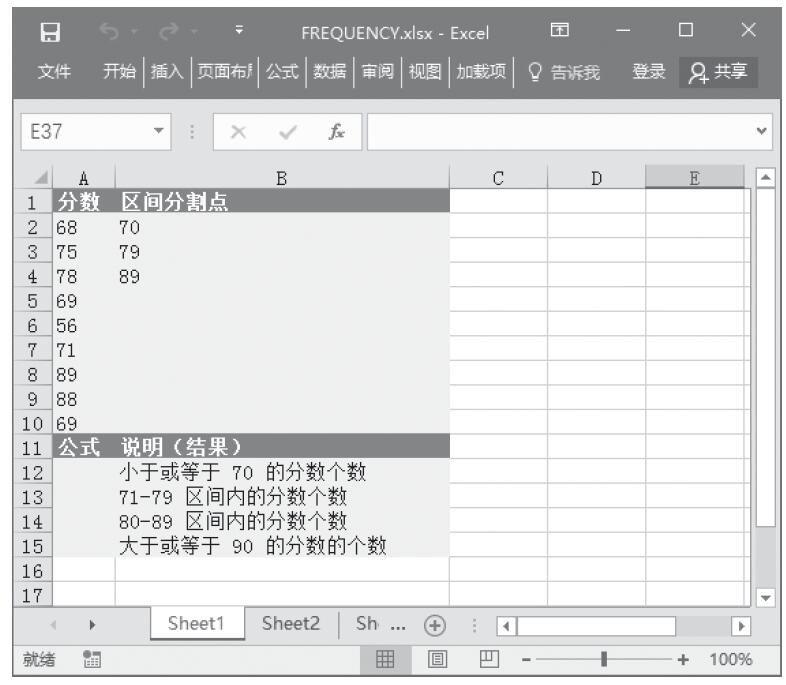
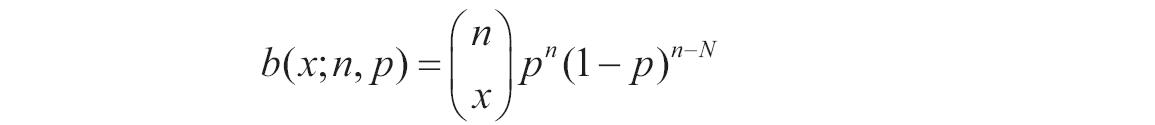
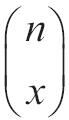 等于COMBIN(n,x)。
等于COMBIN(n,x)。