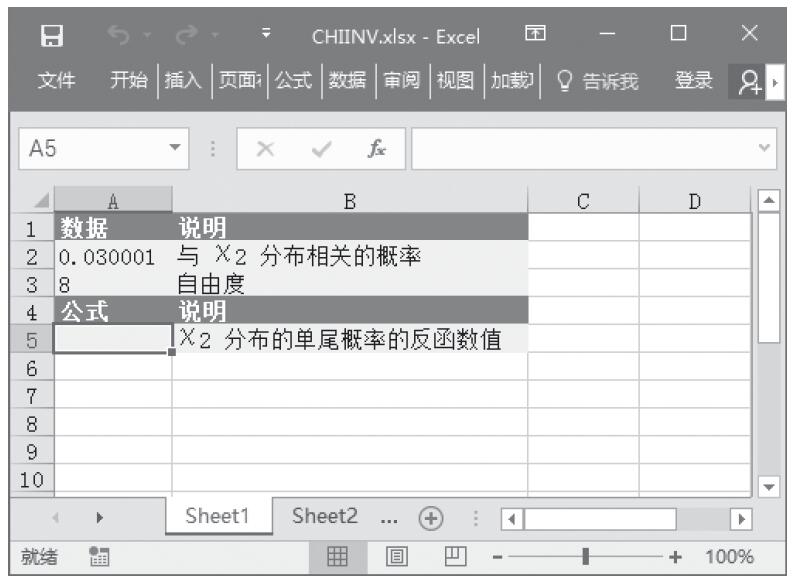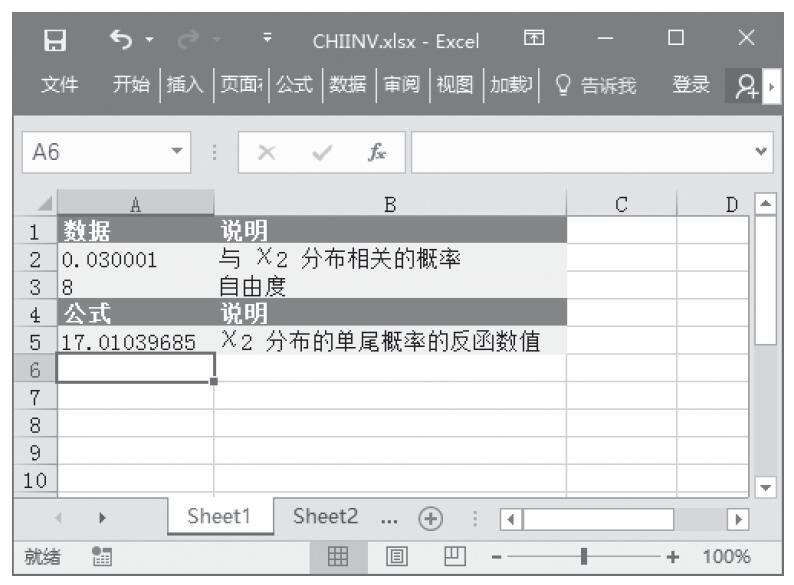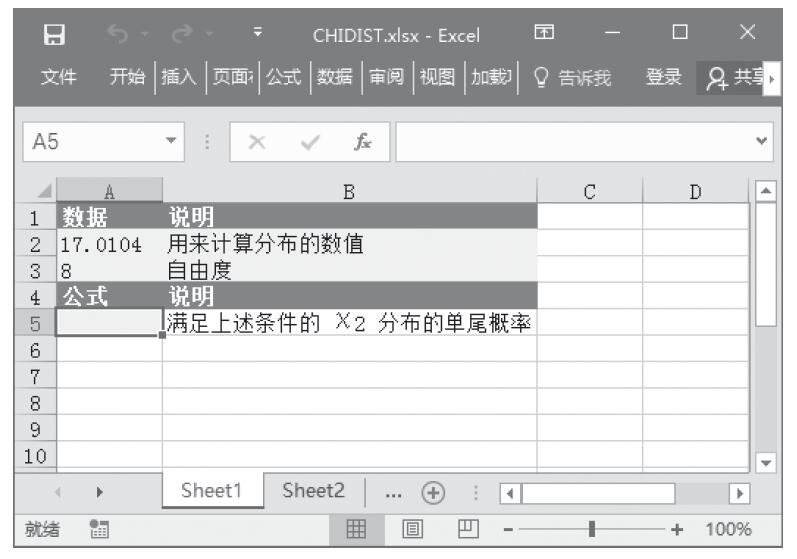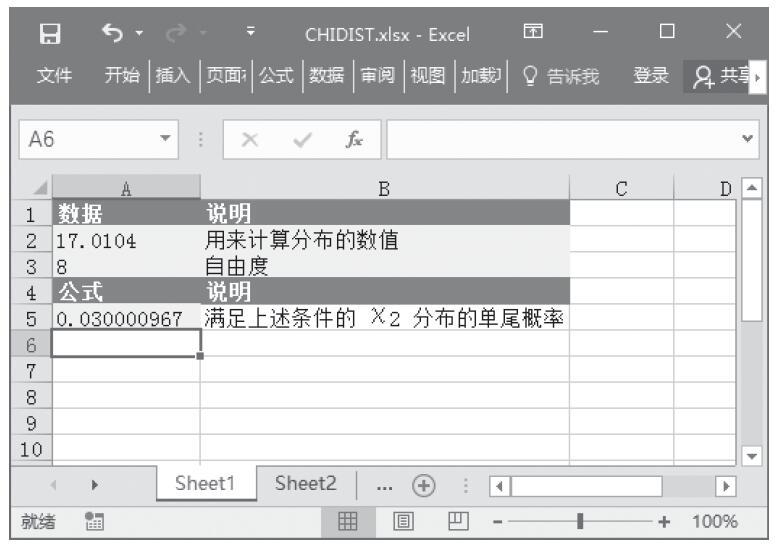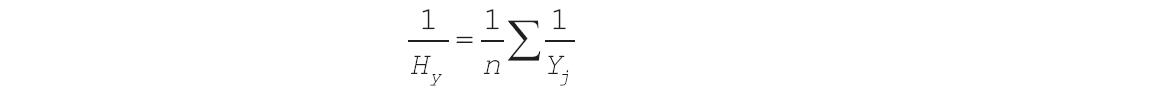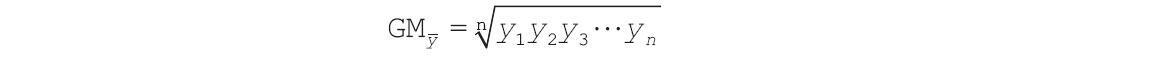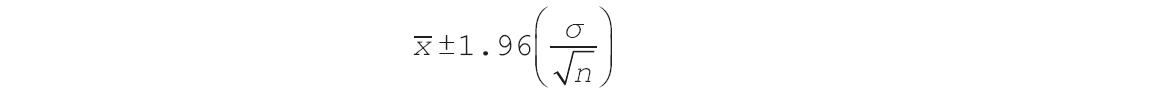
CHITEST函数用于计算独立性检验值。函数CHITEST返回(χ2)分布的统计值及相应的自由度。可以使用(χ2)检验值确定假设值是否被实验所证实。CHITEST函数的语法如下。
CHITEST(actual_range,expected_range)
其中参数actual_range为包含观察值的数据区域,将对期望值作检验。expected_range为包含行列汇总的乘积与总计值之比率的数据区域。
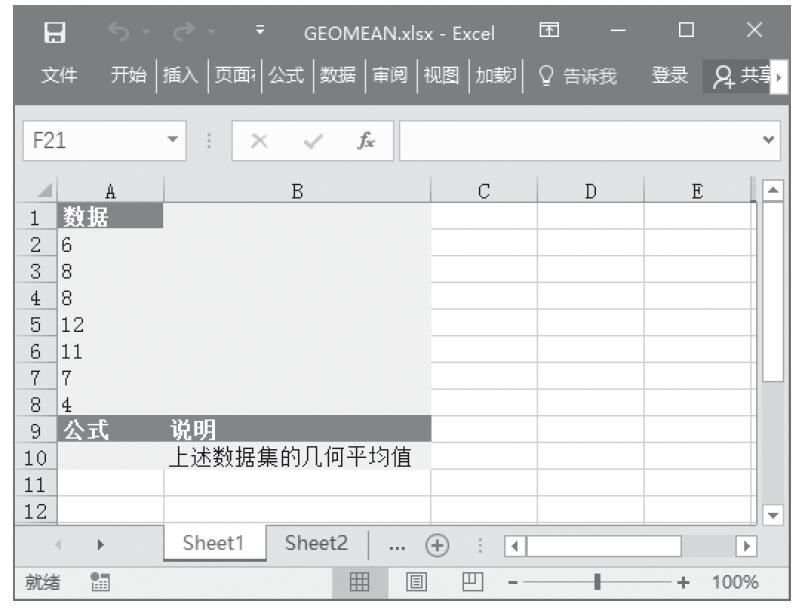
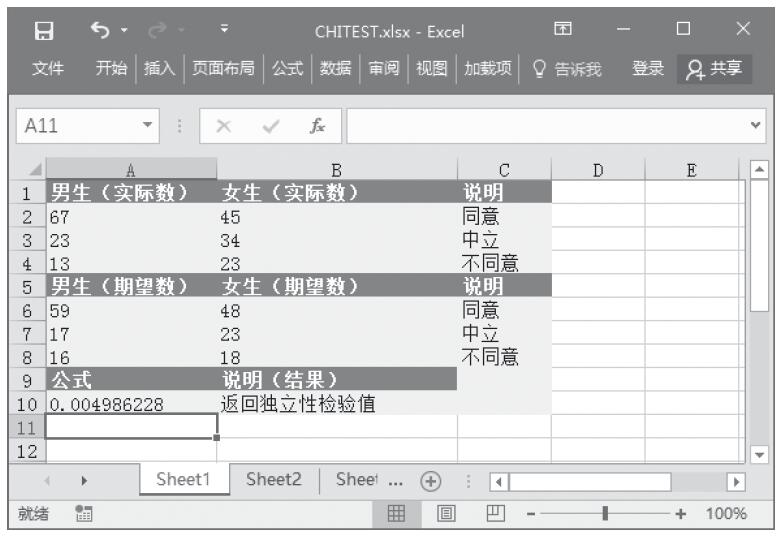
【典型案例】某班统计本班中男生与女生去某地旅游的意向,已知统计的实际数值与期望数值,计算相关性检验值。基础数据如图16-27所示。
步骤1:打开例子工作簿“CHITEST.xlsx”。
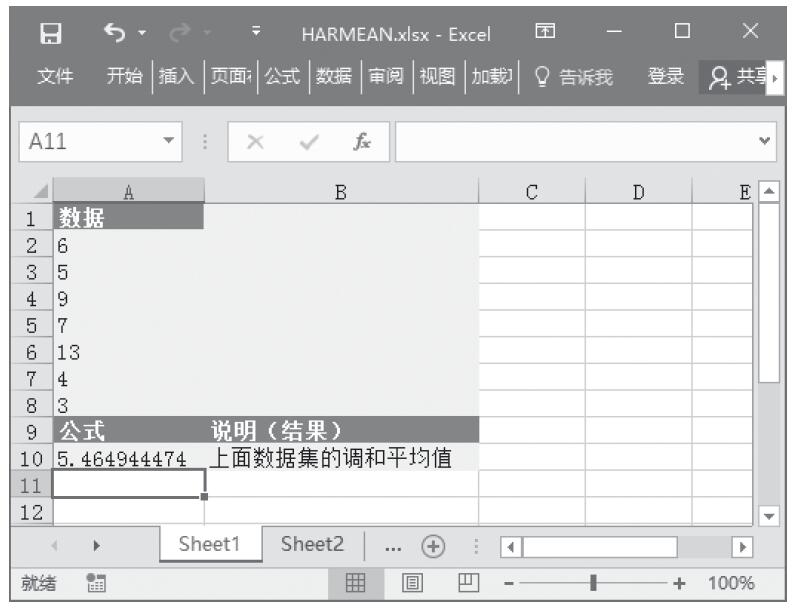
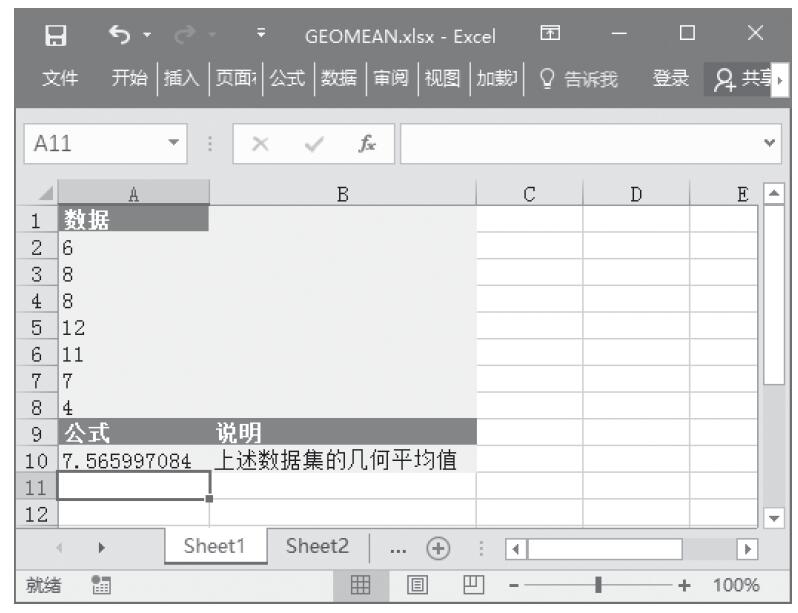
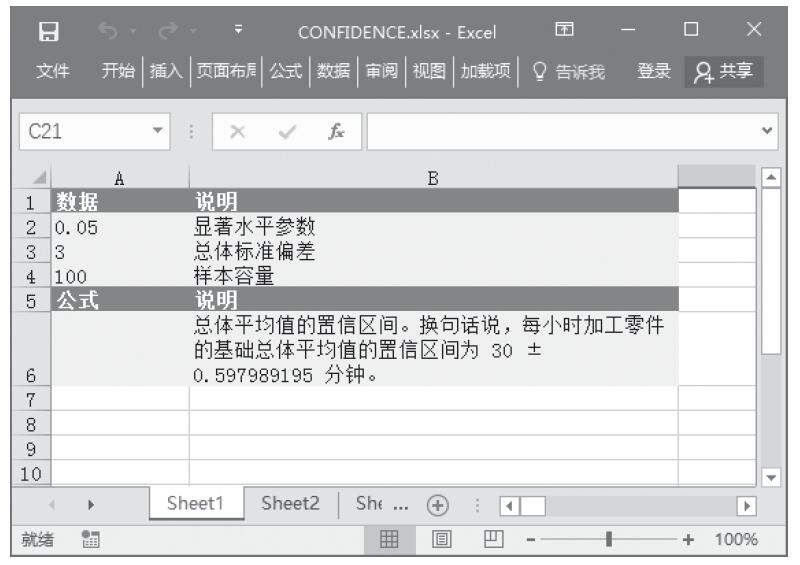
步骤2:在单元格A10中输入公式“=CHITEST(A2:B4,A6:B8)”,用于计算总体平均值的置信区间。计算结果如图16-28所示。
【使用指南】1)如果actual_range和expected_range数据点的个数不同,则函数CHITEST返回错误值“#N/A”。χ2检验首先使用下面的公式计算χ2统计:
 检验
检验式中:
Aij为第i行、第j列的实际频率。
Eij为第i行、第j列的期望频率。
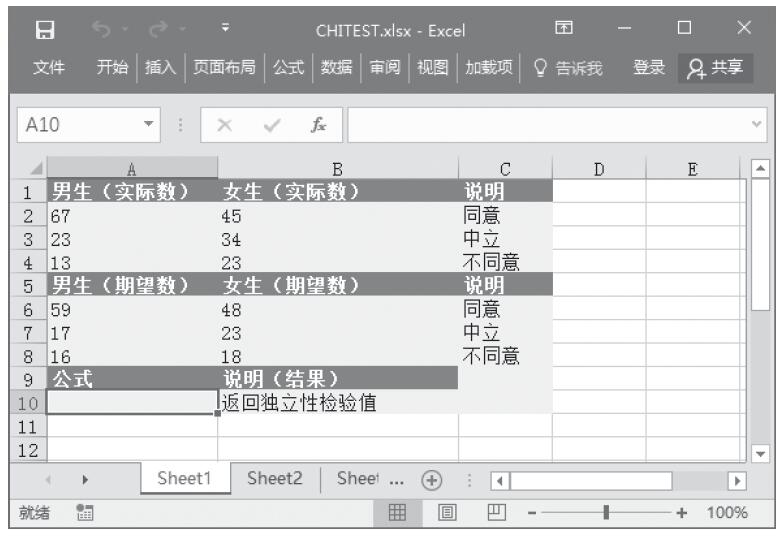
图16-27 基础数据
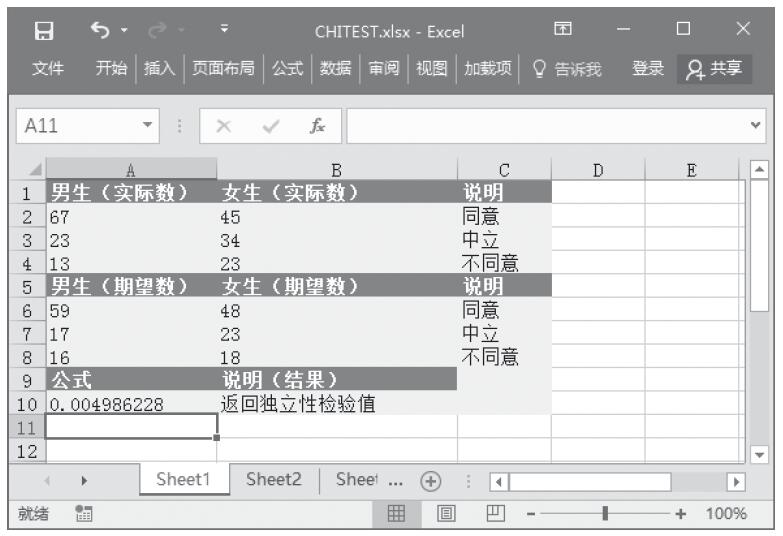
图16-28 计算结果
2)从公式中可看出,χ2总是正数或0,且为0的条件是:对于每个i和j,如果Aij=Eij。
3)CHITEST返回在独立的假设条件下意外获得特定情况的概率,即χ2统计值至少与由上面的公式计算出的值一样大的情况。在计算此概率时,CHITEST使用具有相应自由度df的个数的χ2分布。如果r>1且c>1,则df=(r-1)(c-1)。如果r=1且c>1,则df=c-1。或者如果r>1且c=1,则df=r-1。不允许出现r=c=1并且返回“#N/A”。
4)当Eij的值不太小时,使用CHITEST最合适。某些统计人员建议每个Eij应该大于等于5。