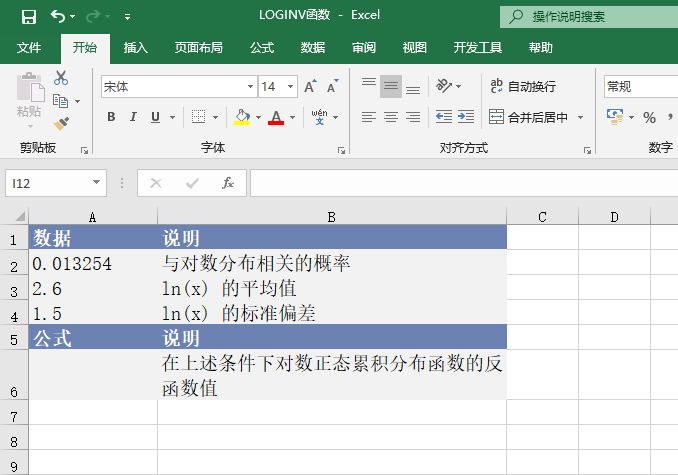
GROWTH函数用于根据现有的数据预测指数增长值。根据现有的x值和y值,GROWTH函数返回一组新的x值对应的y值。可以使用GROWTH工作表函数来拟合满足现有x值和y值的指数曲线。GROWTH函数的语法如下:
GROWTH(known_y's,known_x's,new_x's,const)
其中,known_y’s参数为满足指数回归拟合曲线y=b*m^x的一组已知的y值。known_x’s参数为满足指数回归拟合曲线y=b*m^x的一组已知的x值,为可选参数。new_x’s参数为需要通过GROWTH函数返回的对应y值的一组新x值。const参数为一逻辑值,用于指定是否将常数b强制设为1。下面通过实例详细讲解该函数的使用方法与技巧。
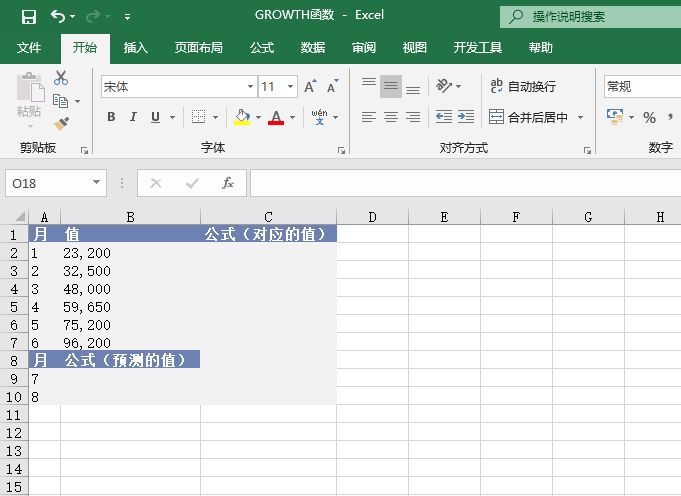
打开“GROWTH函数.xlsx”工作簿,切换至“Sheet1”工作表,本例中的原始数据如图18-23所示。该工作表中记录了一组数据,要求根据现有数据预测指数增长值。具体的操作步骤如下。
图18-23 原始数据
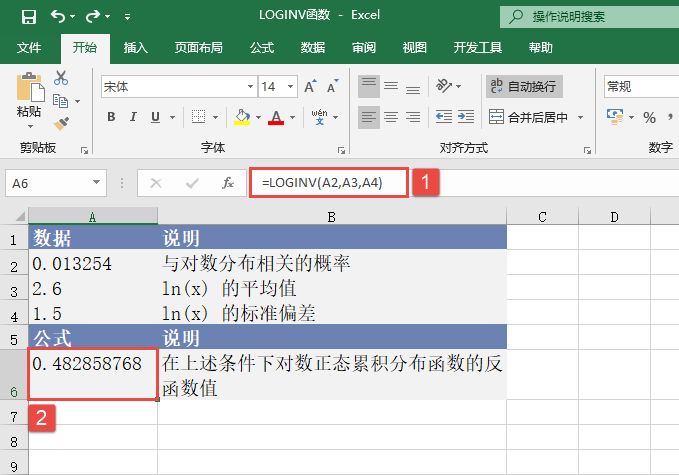
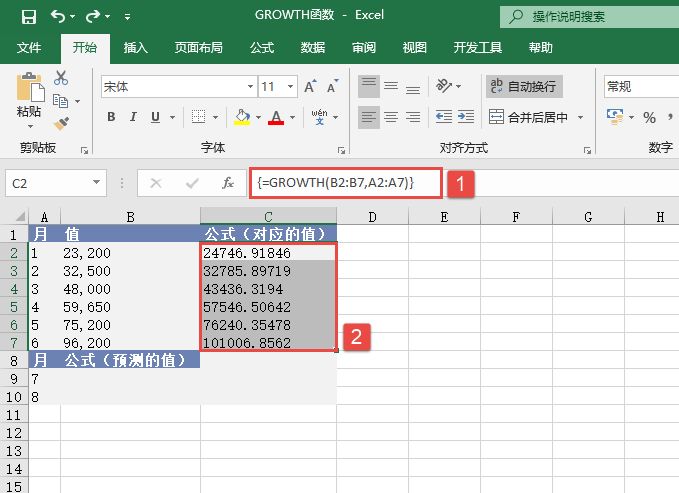
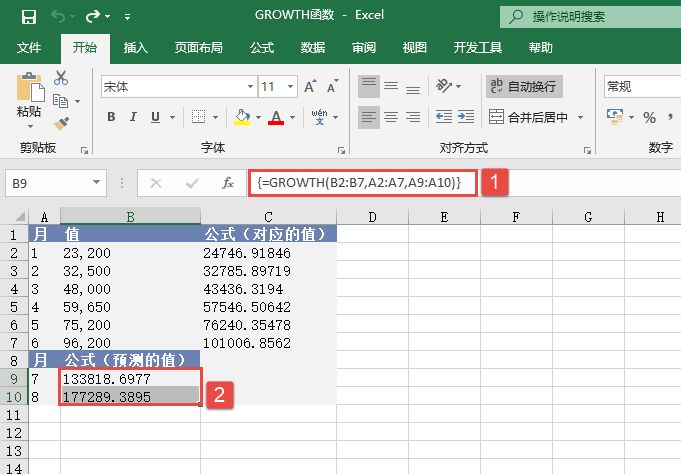
STEP01:选中C2:C7单元格区域,按“F2”键,输入公式“=GROWTH(B2:B7,A2:A7)”,然后按“Ctrl+Shift+Enter”组合键返回数组公式,并得出计算结果,如图18-24所示。
STEP02:选中B9:B10单元格区域,按“F2”键,输入公式“=GROWTH(B2:B7,A2:A7,A9:A10)”,然后按“Ctrl+Shift+Enter”组合键返回数组公式,并得出计算结果,如图18-25所示。
注意:
1)如果数组known_y’s在单独一列中,则known_x’s的每一列被视为一个独立的变量。
2)如果数组known_y’s在单独一行中,则known_x’s的每一行被视为一个独立的变量。
3)如果known_y*s参数中的任何数为零或为负数,GROWTH函数将返回错误值“#NUM!”。
图18-24 计算对应的值
图18-25 计算预测的值
4)数组known_x’s可以包含一组或多组变量。如果仅使用一个变量,那么只要known_x’s参数和known_y’s参数具有相同的维数,则它们可以是任何形状的区域。如果用到多个变量,则known_y’s参数必须为向量(即必须为一行或一列)。
5)如果省略known_x’s参数,则假设该数组为{1,2,3,…},其大小与known_y’s参数相同。
6)new_x’s参数与known_x’s参数一样,对每个自变量必须包括单独的一列(或一行)。因此,如果known_y’s参数是单列的,known_x’s参数和new_x’s参数应该有同样的列数。如果known_y’s参数是单行的,known_x’s参数和new_x’s参数应该有同样的行数。
7)如果省略new_x’s参数,则假设它和known_x’s参数相同。
8)如果known_x’s参数与new_x’s参数都被省略,则假设它们为数组{1,2,3,…},其大小与known_y’s参数相同。
9)如果const参数为TRUE或省略,b将按正常计算。
10)如果const参数为FALSE,b将设为1,m值将被调整以满足y=m^x。
11)对于返回结果为数组的公式,在选定正确的单元格个数后,必须以数组公式的形式输入。
12)当为参数(如known_x’s)输入数组常量时,应当使用逗号分隔同一行中的数据,用分号分隔不同行中的数据。