RANK函数用于计算一个数字在数字列表中的排位。数字的排位是其大小与列表中其他值的比值(如果列表已排过序,则数字的排位就是它当前的位置)。RANK函数的语法如下。
RANK(number,ref,order)
其中参数number为需要找到排位的数字。ref为数字列表数组或对数字列表的引用,其中的非数值型参数将被忽略。order为一数字,指明排位的方式。如果order为0(零)或省略,Excel对数字的排位是基于ref为按照降序排列的列表;如果order不为零,Excel对数字的排位是基于ref为按照升序排列的列表。
典型案例
已知一组数据,计算指定数值在数据集中的排位。基础数据如图16-131所示。
步骤1:打开例子工作簿“RANK.xlsx”。
步骤2:在单元格A8中输入公式“=RANK(A3,A2:A6,1)”,用于计算5.8在上表中的排位。
步骤3:在单元格A9中输入公式“=RANK(A2,A2:A6,1)”,用于计算11.6在上表中的排位。计算结果如图16-132所示。
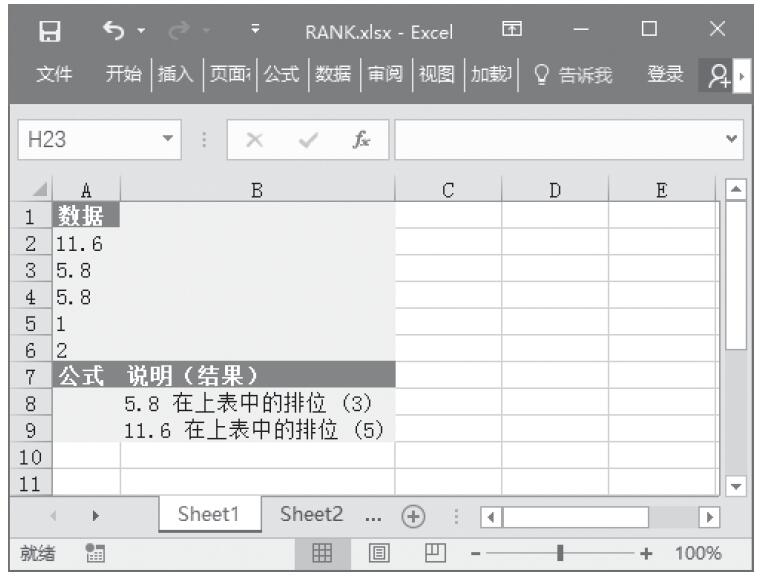
图16-131 基础数据
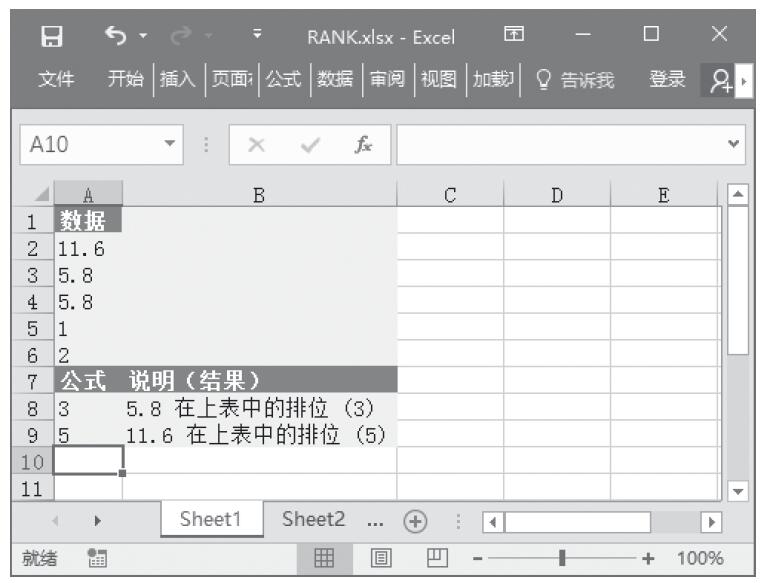
图16-132 计算结果
使用指南
1)函数RANK对重复数的排位相同。但重复数的存在将影响后续数值的排位。例如,在一列按升序排列的整数中,如果整数10出现两次,其排位为5,则11的排位为7(没有排位为6的数值)。
2)由于某些原因,用户可能使用考虑重复数字的排位定义。在前面的示例中,用户可能要将整数10的排位改为5.5。这可通过将下列修正因素添加到按排位返回的值来实现。该修正因素对于按照升序计算排位(顺序为非零值)或按照降序计算排位(顺序为0或被忽略)的情况都是正确的。
3)重复数排位的修正因素=[COUNT(ref)+1–RANK(number,ref,0)–RANK(number,ref,1)]÷2。
4)在上面的示例中,RANK(A2,A1:A5,1)等于3。修正因素是(5+1–2–3)÷2=0.5,考虑重复数排位的修改排位是3+0.5=3.5。如果数字仅在ref出现一次,由于不必调整RANK,因此修正因素为0。